


전력소모와 전송지연 최소화한 메모리 탑재 프로세서
처리 속도 최대 100배 ↑, 전력사용량 GPU 대비 2배 ↓
[테크월드=김경한 기자] 2016년 설립한 신생 AI 반도체 전문 기업인 그래프코어(Grafhcore)가 엔비디아에 도전장을 내밀고 한국 지사 설립을 발표했다.
그래프코어는 지난 2월 4일 서울 그랜드 인터컨티넨탈 서울 파르나스에서 한국 지사 설립 관련 기자간다회를 개최하고 기존 대비 데이터 처리속도를 최대 100배까지 향상시킬 수 있는 ‘콜로서스(Colossus) IPU(Intelligence Processing Unit)를 발표했다. 이날 기자회견장 정면에는 해파리가 바닷속을 물결치는 듯한 형이상학적인 현수막 그림이 걸려있었다. 이에 대해 파브리스 모이잔(Fabrice Moizan) 그래프코어 미국 영업/비즈니스 총괄 부사장은 그래프코어의 콜로서스 IPU가 사람의 뇌와 닮은 프로세서라고 생각해 이를 형상화한 것이라고 밝혔다. 다음은 기자회견 내용이다.

칩 안에 메모리를 탑재한 병렬 코어 방식
콜로서스 IPU는 CPU나 GPU와는 달리 프로세서 안에 메모리를 배치한 제품이다. 이를 통해 트레이닝과 추론 모델을 메모리에 적재한 후 바로 연산할 수 있어 CPU, DRAM, GPU 간 지연이 제거되고 연산 속도가 획기적으로 향상되며, 전력소모도 적다.
파브리스 모이잔 부사장은 “AI 분야에서 트레이닝과 추론을 함께 할 수 있는 칩을 보유한 기업은 구글, 엔비디아, 그래프코어 3곳 밖에 없다”며, “특히 그래프코어의 콜로서스 IPU는 지연이 없고 전력소모도 적어 머신러닝이나 자율주행차에 특화된 프로세서”라고 밝혔다.

콜로서스 IPU는 칩 안에 메모리를 장착했기 때문에 메모리 중심적 아키텍처다. 아키텍처를 통해 구현되는 성능상의 이점을 살펴보면, 카드당 2배 이상의 연산 성능을 향상시킬 수 있으며, 엣지에서의 전송속도 지연을 최소화해 실시간 애플리케이션에서 탁월하고, 기계 학습 소요 시간을 줄이며, 전력 효율적으로 메모리를 사용할 수 있다. 또한 학습과 추론에 동일한 HW와 SW를 사용해 높은 유연성을 제공하며, 엣지로부터 클라우드에 이르기까지 지속적으로 증가하고 있는 새로운 솔루션에 모두 적용할 수 있는 높은 확장성을 제공한다.
상당히 방대한 양의 데이터를 병렬처리할 수 있는 것도 특징이다. 콜로서스 IPU는 1200개 이상의 병렬 코어로 150W에서 125 TFLOPS의 연산속도를 제공하고 7000개 이상의 프로그램을 병렬 실행할 수 있다. 여러 곳에 분산된 데이터를 끌어와서 조합하는 것이 탁월하다.
그래프코어의 IPU는 글로벌 기업의 컴퓨팅 시스템에 이미 채택되고 있다. 2019년 마이크로소프트(MS)는 클라우드 컴퓨팅 플랫폼 '애저(Azure)'에 그래프코어 IPU를 탑재해 고객에게 좀 더 편리한 AI 개발 환경을 제공하고 있다. MS 애저에 IPU가 적용되면 사용자들은 애저 플랫폼 안에서 머신러닝이나 자연어처리(NLP) 등을 활용해 새로운 서비스나 제품을 개발할 수 있게 된다. 또한 그래프코어 IPU는 델(Dell) 서버 랙 기술과 통합되고 있다. 이를 통해 기업 고객이 직접 머신 인텔리전스 컴퓨팅을 구축할 수 있다.
이와 같은 기술력에 힘입어 그래프코어는 보쉬 벤처캐피털, 삼성전자, 델 테크놀로지 캐피털, 아마데우스 캐피털파트너스, C4벤처스, 드라퍼 에스프리트, 파운데이션 캐피털, 피탕고 캐피털, Arm 공동 창업자 헤르만 하우저(Hermann Hauser)와 딥마인드(DeepMind) 공동 창업자 데미스 하사비스(Demis Hassabis) 등으로부터 3억 달러(약 3500억원)를 유치했으며, 현재 기업 가치는 15억 달러(약 1조 7400억 원)로 평가 받고 있다.
파브리스 모이잔 부사장은 “삼성전자로부터 투자를 받았기 때문에 이 자리에 오게 됐다”며, “향후 삼성전자가 AI 시장을 주도하는 업체가 될 것이라 생각한다”고 말했다. 특히 “한국은 흥미로운 시장”이라고 강조하며, “통신분야, 5G, 세계에서 가장 빠른 인터넷 등 혁신적인 기술들이 많이 활용되고 있다. 앞으로 계속해서 세계 시장을 선도하고자 한다면 그래프코어 IPU가 제공하는 기술이 도움이 될 것”이라고 전했다.
이날 파브리스 모이잔 부사장의 발표에 따르면, 그래프코어 IPU는 기존 CPU와 GPU를 사용하는 것과 비교해 데이터 처리 속도가 10배에서 최대 100배까지 빠르고, GPU보다 전력 사용량이 2배 이상 적어 데이터를 분석해서 컴퓨터 스스로 판단하고 학습할 수 있는 능력인 머신러닝에 더 적합하다.
상용제품 C2, 최대 1만 개 프로그램 병렬 처리
그래프코어의 IPU 첫 상용 제품은 지난 2018년 출시한 16nm PCI 고속 카드 ‘C2’이다.
C2는 두 개의 상호 연결된 ‘콜로서스(Colossus) IPU’로 각각 16코어 팩과 236억 개의 트랜지스터로 구성됐다. 단일 칩의 1216 IPU는 코어당 최대 100GFLOPS(1GFLOP은 초당 약 10억 부동 소수점 연산에 해당)이상으로 300MB 메모리와 짝을 이룰 수 있으며 최대 1만 개의 프로그램을 병렬로 실행할 수 있다.
그래프코어 IPU의 칩당 메모리 대역폭은 45TB/s로 ‘C2’에 90TB/s의 전체 카드 대역폭을 제공한다. 이론적인 최대치는 HBM2 그래픽 칩 메모리보다 100배 이상 높은 것이다.
‘C2’는 AI 머신러닝을 위해 고안된 자사의 소프트웨어 스텍 ‘포플러(Poplar)’와 함께 작동하도록 설계됐다. 구글 텐서플로우 프레임워크와 호환할 수 있는 AI 모델 생태계 ONNX(Open Neural Network Exchange)과 통합됐다. 페이스북 파이토치(PyTorch)와 호환도 2020년 초까지 완료한다는 계획이다.
실제 사례로, 그래프코어는 IPU의 효율성을 입증하기 위해 구글 버트(BERT)를 활용했다. 이 모델은 일련의 데이터 세트를 사전 훈련해 문장 간의 관계를 학습하는 언어 모델이다. 이 모델에 자사 제품을 적용했을 때 한 대의 IPU 서버가 8개의 C2카드를 탑재, 56시간 동안 하나의 버트 베이스를 훈련하고 평균적으로 출론 처리량이 3배, 대기시간이 20% 이상 향상됐다는 것이 그래프코어의 주장이다.
이미지 인식 측면에서는, 프랑스의 검색엔진 회사 '콴트(Qwant)'는 그래프코어의 IPU를 시스템에 적용한 이후 페이스북 모듈형 ‘ResNeXt-101’ 아키텍처를 실행하는 데 성공했으며, 이미지 검색 속도가 3.5배 빨라졌다고 한다.
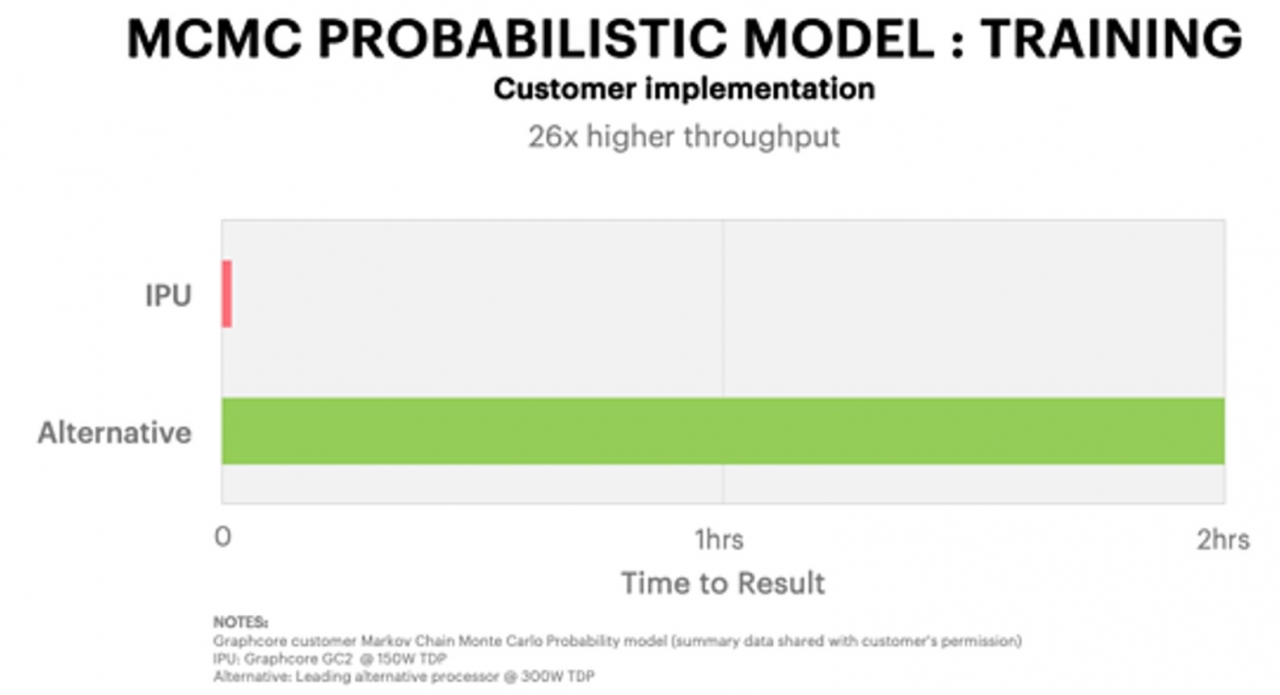
확률론 학습 MCMC(Markov Chain Monte Carlo) 기반 모델에서도 그래프코어의 IPU를 적용하여 기존 하드웨어로 2시간 이상 걸린 작업을 4분 30초 만에 최적화할 수 있었다. 훈련 시간은 26배 빨랐다.
오토인코더(AutoEncoder) 모델은 온라인 TV 시청자들에게 영화를 추천하는 추천시스템에서 필터링을 수행하는 데 사용될 수도 있다. 이 자동 인코더 모델은 공개된 넷플릭스(Netflix) 데이터 세트를 사용해 '협업적 필터링을 위한 심층 오토엔코더 훈련' 논문 기반 모델로 테스트한 결과 C2는 동급 전력으로 선도 프로세서에 비해 2배 이상 성능을 보였다.
GPU 대체재 아니다?
그래프코어의 발표가 끝나자 기자들의 질문이 쏟아졌다. 발표 내용에 따르면, 콜로서스 IPU가 모든 면에서 CPU나 GPU보다 월등히 뛰어난 것처럼 묘사됐기 때문이다.
먼저 기자들은 IPU가 GPU보다 뛰어난 성능을 지녔다는 주장인지를 질문했다.
파브리스 모이잔 부사장은 “그래프코어의 창업자가 IPU가 기존의 기술을 대체하거나 향후 10년 내에 발생할 수 있는 문제를 해결하자는 취지로 만든 프로세서”라며 직접적인 답변을 피했다. 그러면서 “창업자는 GPU를 대체하기보다는 업계 관계자를 만나면서 어떤 문제가 있는지 조사하고 상당히 오랜 기간에 걸쳐 발생할 수 있는 문제를 해결할 수 있는 아키텍처를 구축하길 원했고, 그래서 ‘온칩메모리’라는 아이디어를 생각해 냈다”고 설명했다.
또한 IPU가 GPU를 대체하기 위해 출시한 제품인지에 대한 질문에 대해선 “IPU가 적합한 회사가 있고, GPU가 적합한 회사가 있다. 애플리케이션에 따라 달라질 수 있다”며 다소 모호한 답변을 내놨다.
파브리스 모이잔 부사장은 “IPU가 다른 프로세서의 비해 100%의 최고 성능을 지니면 좋을 것”이라면서도 “GPU는 큰 이미지를 처리하는 데 장점이 있다면, IPU는 배치 사이즈가 작은 경우에 유리하다. 또한 자연어 처리와 데이터가 분산된 경우에 탁월한 성능을 지닌다”고 주장했다.
특히 그는 “엔비디아의 GPU는 카드에 하나의 칩이 들어가지만, IPU는 같은 가격에 두 개의 칩이 들어가기 때문에 가격경쟁력도 우수하다”고 역설했다.
그래도 삭제하시겠습니까?