


인간과 기계가 막힘없이 대화하려면 기계의 반응이 빠르고 지능적이어야 하며, 그 소리는 자연스럽게 들려야 한다. 하지만 언어처리신경망 개발자들은 그동안 반응 속도와 대화의 품질 사이에서 절충점을 찾을 수밖에 없었다. 속도를 높이면 대화의 품질이 떨어지고, 지능적으로 대답을 하려니 긴 반응 시간이 필요했기 때문이다.
인간의 대화란 것이 그처럼 복잡하다. 모든 말은 참여자들이 공유하는 대화의 맥락과 그전에 있었던 상호작용에 기반해 이뤄진다. 가까운 사람끼리 주고받는 농담이나 문화적인 배경, 말장난 등에 있어 인간은 당황하지 않고 재치 있는 대화를 나눈다. 그리고 이 모든 반응은 직전에 있던 반응에 따라 이뤄지는 것이다. 그래서 때때로 우린 친구가 입을 떼기도 전에 무슨 말을 할지 예상할 수도 있다.

대화형 인공지능이란
대화형 인공지능(AI)이란 대화의 맥락을 이해하고 지능적인 반응을 통해 사람과 유사한 수준의 대화가 가능한 음성 AI를 말한다. 기업은 GPU에 최적화된 언어인지 모델을 의료, 리테일, 금융 서비스 같은 산업에서 사용되는 AI 애플리케이션과 통합해 스마트 스피커나 고객지원 제품군에서 고급 디지털 음성지원 서비스를 제공할 수 있다. 궁극적으로 고수준의 대화형 AI 도구는 기업이 고객과 소통할 때 과거에는 불가능했던 수준의 개인화 서비스를 실현할 수 있도록 돕는다.
하지만 이런 AI 모델이 작동하려면 방대한 자연어 데이터와 복잡한 처리 알고리즘이 필요하다. 문제는 모델의 크기가 크면 클수록 질문에 대한 AI의 반응 시간은 길어지고 반응 시간이 10분의 2초(200ms, 밀리세컨드)를 넘으면 대화가 부자연스럽게 느껴지기 시작한다는 것이다.
그러나 엔비디아의 GPU와 쿠다(CUDA)-X AI 라이브러리를 사용하면 단 몇 밀리세컨드, 수천 분의 일초 만에 대형 최첨단 언어 모델을 빠르게 학습시키고 AI가 반응할 수 있도록 최적화할 수 있다. 이는 개발자들이 속도와 품질 사이에서 절충을 고민할 필요를 줄여준다는 점에서 의미가 있다.
대화형 AI의 적정 속도
자연스러운 대화를 위한 답변의 공백 시간은 약 200ms다. 다층적인 업무를 수행하는 기업의 대화형 AI가 인간 수준의 상호작용을 하려면 10개 이상의 신경망을 200ms 이내에 작동시켜야 한다. 그리고 AI가 하나의 질문에 대답하는 과정은 사용자의 언어를 문자로 전환하는 것부터, 문자의 의미를 이해하고, 맥락에 맞는 최상의 답변을 검색한 뒤, 텍스트-음성 변환 툴을 거쳐 답변을 제공하기까지 여러 단계를 필요로 한다
이 과정에서 다수의 AI 모델이 사용되는데, 각각의 망에 주어진 처리 한계는 고작 10ms 미만이다. 만약 이 이상 처리 시간이 길어지면 전체 반응 속도가 느려져 대화가 부자연스러워진다.
미래의 대화형 AI는 어떤 일을 할 수 있을까?
물론 모든 업무에 대화형 AI가 필요한 건 아니다. 업무 중요도에 따라 미리 프로그래밍 된 대기행렬(Queue)을 통해 사용자를 안내하는 폰 트리(Phone tree) 알고리즘(‘비행기 티켓 예약을 원하실 경우, 예약이라고 말하세요’와 같은 프롬프트 사용) 같은 기본적인 음성 인터페이스를 이용해 업무를 수행할 수도 있을 것이다. 하지만 폰 트리가 고객이 던진 미묘한 질문의 의미를 이해하거나 문제를 지능적으로 해결해줄 순 없다.
현재 시장에 출시된 음성비서 제품들은 많은 일을 처리하고 있지만 이 중에는 수십억 단위가 아닌 단 수백만 가지의 변수만 고려해 개발된 제품들이 많다. 이런 AI 툴은 제시된 질문에 답변하기 전에 ‘검색해보겠습니다’와 같은 답변을 한 뒤, 그대로 대화가 중단되는 경우가 잦다. 혹은 음성답변 대신 인터넷 검색 결과 목록을 보여주기도 한다. 한계가 명확하다.
따라서 다량의 데이터를 적절한 알고리즘으로 학습한 미래의 대화형 AI는 이보다 높은 수준의 답변을 줄 것이다. 이상적으론 입출금 내역서나 의사의 진단서에 대한 사용자의 질문을 정확히 이해할 정도로 수준이 높고, 자연어로 거의 즉시 답변할 수 있어야 한다.
이런 기술이 제대로 구현된다면 환자의 다음 진료나 체혈 검사 시간을 예약하는 병원용 음성비서, 화가 난 고객에게 택배 도착 시간이 늦어진 이유를 설명하고 포인트 적립을 도와주는 리테일용 음성 AI 등 다양한 분야에 적용될 수 있다. 시장에서도 이런 고급 대화형 AI 툴에 대한 수요가 증가하는 추세다. 2020년까지 전체 검색 중 약 50%가 음성으로 진행될 것이고, 2023년까지 전 세계적으로 80억 개의 디지털 음성비서가 사용될 것이란 전망도 있다.
최신 대화형 AI의 중심 모델, 버트(BERT)
2018년 11월 구글이 공개한 버트(Bidirectional Encoder Representations from Transformers, BERT)는 대형 컴퓨팅 집약적 대화형 AI 모델로, 최첨단 자연어 이해의 새로운 기준을 제시한 모델이다.
약 33억 개 단어로 이뤄진 언어 자료를 학습한 버트는 뛰어난 언어이해 능력이 특징이며 심지어 일반인보다 더 나을 때도 있다. 버트의 강점은 레이블이 없는 데이터 세트 학습 능력이다. 또 최소한의 수정만으로 독해, 감정 분석, 문답 등 광범위한 언어 업무에 적용할 수 있다는 것도 버트만의 강점이다.
뿐만 아니라 버트는 복수의 언어를 이해할 수 있으며 번역, 자동완성기능, 검색 결과 순위 지정 등 구체적인 작업 수행을 지원한다. 복잡한 자연어 이해 개발에 버트가 널리 이용되고 있는 이유다. 최신 생명과학 문서용 버트(BioBERT), 과학 분야 간행물용 버트(SciBERT) 등 현재 모든 도메인 상에서 선두주자로 불리는 언어처리 모델들은 모두 버트에 기반한 모델이다.
이런 버트의 기간 기술은 트랜스포머 레이어(Transformer layer)다. 트랜스포머 레이어란 주의집중 기술(Attention technique)을 적용하는 순환 신경망(Recurrent neural networks)의 대안 기술로, 문장을 분석할 때 그 앞뒤로 오는 단어 중 가장 관련성이 높은 단어에 집중하는 기술이다.
예컨대, “There’s a crane outside the window(창밖에 크레인이 있다)”라는 문장에서 크레인(Crane)은 문장 뒤에 ‘of the lakeside cabin(호숫가 오두막)’라는 구절이 있으면 ‘학’으로 해석될 수도 있고, ‘of my office(사무실)’라는 구절이 있으면 건설 현장에서 사용되는 ‘크레인’으로 해석될 수도 있는데, 버트와 같은 언어 모델은 양방향 인코딩, 또는 무지향성 인코딩(Bidirectional or nondirectional encoding) 기법을 활용해 각각의 상황에서 맥락을 보고 그 문장이 어떤 의미인지 이해할 수 있다.

엔비디아 기술로 트랜스포머 모델을 최적화하는 방법
엔비디아의 GPU 병렬 처리 기능과 텐서 코어(Tensor Core) 아키텍처는 복잡한 언어 모델을 이용해 작업을 할 때 높은 처리량과 확장성을 제공해 버트의 학습과 인퍼런스(Inference, 반응·추론) 면에서 기록적인 성과를 도출해준다.
3억 4000만 개의 매개변수를 제공하는 버트-라지(BERT-Large) 모델 학습 시, 엔비디아의 DGX 슈퍼POD(SuperPOD) 시스템을 사용하면 통상적으로 며칠이 걸리는 학습시간을 단 1시간 이내로 크게 줄일 수 있다. 실시간 대화형 AI의 경우에는 인퍼런스 시간을 크게 줄여준다.
엔비디아 개발자들은 텐서RT(TensorRT) 소프트웨어를 사용해 1억 1000만 개의 매개변수를 제공하는 인퍼런스용 버트 기반 모델을 최적화한 바 있다. 엔비디아 T4 GPU를 사용하는 이 모델은 미국 스탠포드 대학에서 시작된 AI 언어지능 연구용 질의응답 학습 데이터셋인 스쿼드(The Stanford Question Answering Dataset, SQuAD)를 이용해 검사했을 때 단 2.2ms 안에 답변을 계산해냈다. 스쿼드는 AI 언어 모델의 맥락이해 능력 검사에서 널리 사용되는 기준이다.
현재까지도 많은 실시간 애플리케이션의 지연시간 임계값(Latency threshold)은 10ms 수준이다. 고도로 최적화된 CPU 코드의 처리 시간도 40ms를 넘는다. 따라서 엔비디아의 기술을 활용해 인퍼런스 시간을 몇 밀리세컨드로 줄일 수 있다면 버트를 실제 생산 현장에 배치할 수 있게 된다. 버트뿐 아니라, GPT-2, XL넷(XLNet), 로버트a(RoBERTa)와 같은 다른 대형 트랜스포머 기반 자연어 모델을 가속하는 데 동일한 기법을 사용할 수 있다.
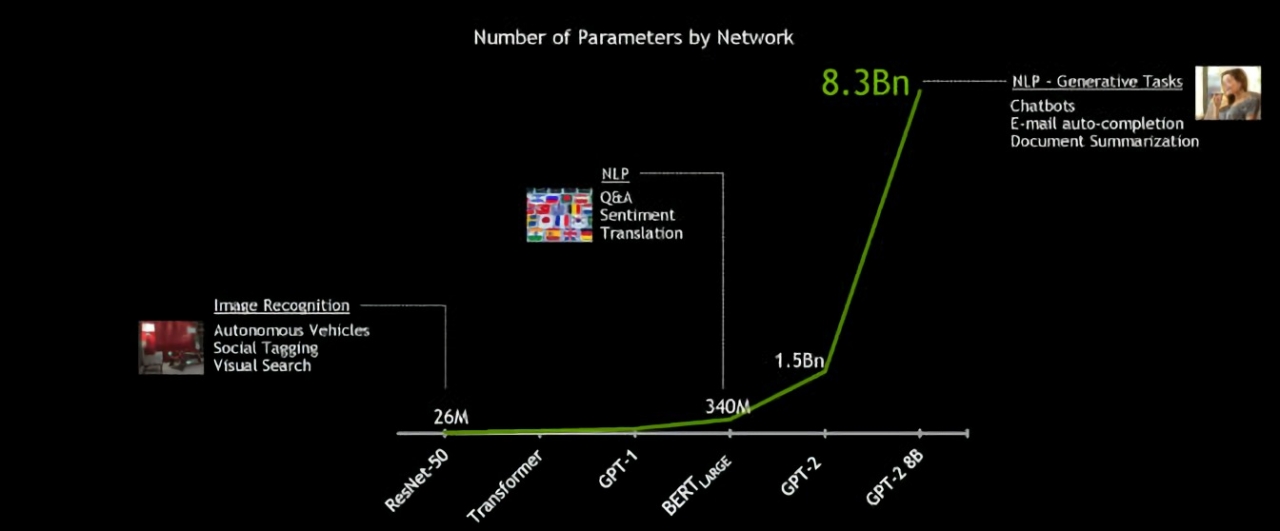
진정한 대화형 AI라는 꿈을 달성하기 위해 언어 모델들의 크기는 갈수록 커지고 있다. 또한 미래의 모델들은 현재 사용되는 모델보다도 크기가 더욱 커질 것이다. 이에, 엔비디아는 현존하는 트랜스포머 기반 AI 중 가장 큰 오픈소스 모델인 GPT-2 8B을 개발했다. GPT-2 8B은 버트-라지 대비 24배나 크고, 83억 개의 매개변수를 제공하는 언어처리 모델이다.
글 | 싯다르타 사르마(Siddharth Sharma)
엔비디아 인공지능 소프트웨어 수석 기술 마케팅 매니저
- 이 글은 테크월드가 발행하는 월간 <EMBEDDED> 2019년 10월호에 게재된 기사입니다.
그래도 삭제하시겠습니까?