


신규 GPU의 기능과 엔비디아 GPU·서버 구조 이해하기
[테크월드=선연수 기자] 엔비디아(NVIDIA)가 지난 10월 5일부터 9일까지 5일간 엔비디아 GTC 2020 행사를 통해 다양한 기술을 공유했다. 그중 지난 5월 출시한 엔비디아의 ‘A100 텐서코어(Tensor Core) GPU’에 대해, 엔비디아 솔루션 아키텍트·엔지니어링 부문 이종환 데이터 사이언티스트의 발표로 자세히 알아봤다.

A100 텐서 코어 GPU의 핵심 기능
엔비디아의 새로운 암페어(Ampere) 아키텍처에 기반한 A100 텐서 코어 GPU는 고성능 컴퓨팅(HPC, High Performance Computing), 인공지능(AI), 데이터 분석 워크로드를 이전 아키텍처 GPU 대비 더 빠른 속도로 처리할 수 있도록 한다.
각 모델이나 알고리즘마다 차이가 있으나 기존의 GPU와 피크(Peak) 데이터로 비교했을 때 FR32 학습(Training)은 20배, INT8 추론(Inference)은 20배, FP64 HPC에서는 2.5배의 성능 우위를 가진다.
새로운 멀티 인스턴스 GPU(MIG, Multi Instance GPU) 기능을 활용해, 1개의 A100 텐서 코어 GPU를 7개의 작은 GPU 인스턴스로 물리적으로 분할해 사용할 수 있도록 지원한다.
이종환 데이터 사이언티스트는 A100 텐서 코어 GPU의 성능 향상의 주요한 요인을 5가지로 꼽았다.
새로운 암페어 아키텍처는 스케일러빌리티(Scalability)를 염두에 두고 개발됐으며, 크고 작은 워크로드, 엑셀레이션 수요에 대응해 최적의 성능을 낼 수 있도록 만들어졌다.

연산 입장에서 가장 큰 변화를 겪은 건 3세대 텐서 코어(3rd Gen Tensor Cores)다. A100 텐서 코어 GPU에서는 312테라플롭스(TFLOPs)를 피지컬로 연산할 수 있으며, 딥러닝 학습과 추론에서 V100 GPU 대비 연산 능력(Compute Capability)이 20배가량 늘었다.
새로 도입된 멀티 인스턴스 GPU 기능은 제품을 최대 7개의 GPU 인스턴스(Instance)로 분리·사용하는 기술이다. 분리된 인스턴스는 하드웨어적으로 아이솔레이션(Isolation)돼 메모리 대역폭(Bandwidth), 컴퓨트 코어의 인스턴스 등이 서로 충돌없이 사용할 수 있도록 한다. 사용자는 목적에 따라 필요한 캐패시티로 묶어 여러 용도로 인스턴스를 활용할 수 있다.
이외에도 AI 모델에서 하네스(Harness) 스파시티(Sparsity) 가속화로 AI 성능을 2배 이상 높였고, 3세대 NV링크(NVLink)가 추가돼 GPU간 통신에서 대역폭을 2배 정도 늘렸다.
FP32로 버트 라지(BERT Large)모델 학습 시의 성능을 비교해보면, A100은 모델 컨버지(Converge) 시 V100 대비 6배의 성능 우위를 나타냈다. 추론은 V100 대비 7배 우수했으며, 이는 A100를 7개로 나눈 것 중 하나가 V100과 맞먹는 셈이다. HPC 벤치마크는 A100이 V100 대비 1.5~2.1배의 성능 개선을 기록했다.
엔비디아 GPU의 기본 구조
엔비디아의 GPU는 단일 GPU의 역할을 수행하는 GPC(Graphics Processing Cluster)가 존재하고, 그 내부에 TPC(Texture Processor Cluster)가 존재한다. TPC 내부에는 SM(Streaming Multi Processor)가 존재하고, 이 안에는 서브 코어들이 존재한다. 서브 코어 속에는 텐서 코어와 쿠다 코어가 들어있다.
A100으로 살펴보면, 각 7개의 단일 GPC 내부에 TPC가 8개씩 있고, 한 개의 TPC당 SM이 2개씩 장착된다. 하나의 SM 속에는 서브 코어 4개가 존재하고, 하나의 서브 코어에는 텐서 코어 1개와 여러 쿠다 코어들이 들어간다. FP32bit 연산 처리를 위한 쿠다 코어 엔진은 서브 코어 1개 당 16개가 집적된다. 전체 GPU에는 쿠다 코어는 총 6912개, 텐서 코어는 432개가 자리 잡게 된다.
엔비디아 DGX A100 서버의 구조
A100 텐서 코어 GPU 8개가 모여 만들어진 레퍼런스 서버 아키텍처가 ‘엔비디아 DGX A100’이다. 8개의 GPU는 각각 40GB를 제공해 서버는 총 320GB의 GPU 메모리를 가진다. GPU끼리 연결할 수 있는 3세대 NV링크와 6개의 NV스위치(NVSwitch)가 존재해, GPU 간 통신에 4.8TB/s의 바이 디렉셔널(Bi-directional) 대역폭으로 이전 세대 대비 2배 큰 NV스위치 대역폭을 지원한다.
CPU로는 AMD Rome 7742를 사용하며, 이는 각각 2.25~3.4 GHz의 동작 주파수로 작동한다. 시스템 메모리로는 1TB를 가지고 있으며 스토리지는 15TB의 젠4(Gen4) NVMe SSD를 가진다.
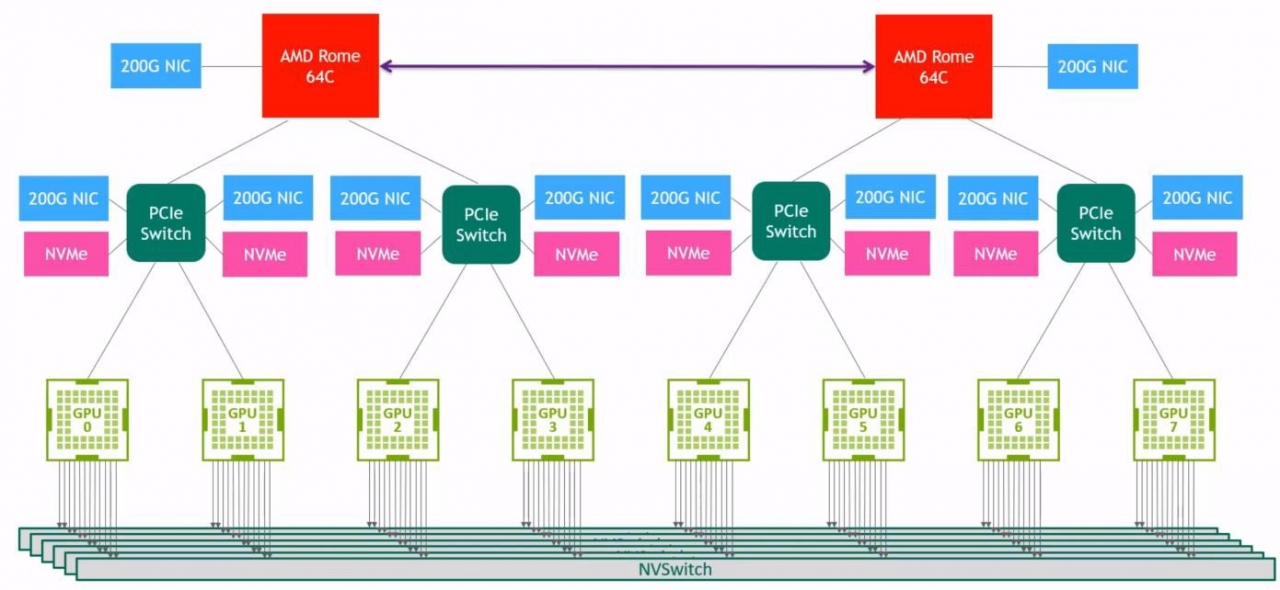
DGX A100은 A100 텐서코어 GPU 8개와 닉(NIC) 9개가 있으며, 각 텐서코어 GPU 간 인터커넥션(Interconnection)은 GPU별 NV링크와 6개의 NV스위치를 통해 이뤄진다. 따라서 내부 서버에서 갖는 토폴로지는 [그림 3]과 같으며, 연결된 GPU들은 서로 600GB/s의 대역폭을 가진다. 이렇게 구성된 DGX A100은 AI 연산과 관련해 5페타플롭스(PFlops)의 성능을 달성한다.
DGX A100에서는 각 GPU에 다른 워크로드를 배정할 수 있다. 4개는 학습, 2개는 데이터 분석, 나머지 2개는 MIG 기능을 이용해 7개의 슬라이스로 분리함으로써 각각 다른 추론 과제를 배정하는 방식을 활용할 수 있다.
이종환 데이터 사이언티스트는 “현재 A100 텐서 코어 GPU가 장착된 GPU 서버는 DGX A100이 유일하다. 이 아키텍처에 기반한 HGX-A100 4-GPU와 HGX-A100 8-GPU를 제공 중이며, 추후 OEM을 통해 만나볼 수 있을 것”이라고 전했다.
그래도 삭제하시겠습니까?