

[테크월드뉴스=서유덕 기자] “[기고] 인공지능 반도체는 어디에서 와서 어디로 가고 있는가? (1)”에서 이어지는 기사입니다.

1970년대 초반부터 반도체의 집적도는 비약적으로 향상돼 왔다. 1971년 출시된 인텔 4004는 2300개의 트랜지스터로 구성됐는데, 2020년 11월 애플이 발표한 M1 칩셋은 인텔 4004 대비 약 700만 배인 160억 개의 트랜지스터를 집적했다.

수많은 트랜지스터와 큰 게이트 규모를 작은 칩에 집적하는 기술의 끝은 어디로 가고 있을까? TSMC와 삼성전자는 7나노(㎚) 이하의 미세공정을 생산하는 유이한 회사다. 10㎚ 공정까지의 포토-리소그래피는 기존의 아르곤 불소(ArF) 엑시머 레이저(파장 길이 193㎚)를 사용 가능하지만, 그 이하의 공정에서는 극자외선(EUV, 파장 길이 13.5㎚)이 필요하다.
그런데 파장이 짧을수록 장비에서 반사판으로 흡수되는 에너지가 많아져 최종 웨이퍼에 도달되는 빛이 너무 적어지는 문제가 생긴다. 실리콘 웨이퍼에 빛을 조사해서 미세한 회로를 그려야 하는데, 에너지가 중간에 많이 손실되면서 회로 형성에 많은 시간이 소요되는 것이다. 이것은 마치 800㎒ 통신망을 사용할 때 기지국 수가 많지 않아도 잘 터지던 전파가 2.2~5㎓를 넘어 최근의 5G 밀리미터파로 이행할수록 기지국을 많이 세워 촘촘한 망을 구축해야만 원활한 통신이 이뤄지는 것과 비슷하다. 이는 전파가 장파장에서 단파장으로 가면서 회절성이 줄고 직진성이 느는 원리에서 기인하며, 따라서 극자외선 장비 같은 고정밀 시스템은 공기 저항을 최소화하기 위해 진공에서 동작한다. 심지어 장비 동작 온도 편차가 0.001℃ 내외라는 말까지 존재한다.
이런 고정밀 극자외선 장비를 공급하는 유일한 회사가 바로 네덜란드의 ASML이다. 이런 관계로 EUV 장비는 거의 ASML이 제시하는 가격으로 거래되는 ‘부르는 게 값’인 상황이며, 그나마도 지금은 없어서 못 구하는 것이 현실이다.

한편, 파장 길이가 193㎚ 이하로 짧아지면 EUV 장비 내 파장 반사를 위한 반사경에서 많은 에너지를 흡수하게 된다. 따라서 1㎚ 공정까지는 개발 가능하더라도, 100~10피코미터(pm)의 회로 선폭으로 개발하기는 어렵게 된다.
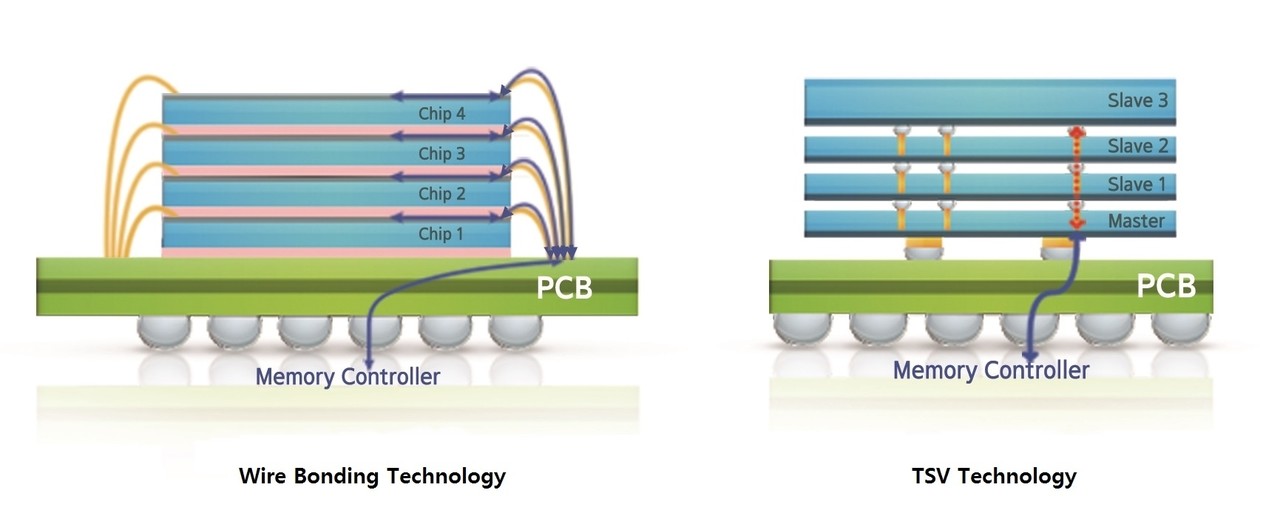
미세 회로 선폭이 1㎚에 그치면 인공지능(AI) 반도체 집적도는 한계에 이를 것인가? 필자는 팹리스 업체 대표로서 AI 반도체를 포함한 반도체 설계와 개발 사업에 주력하느라 제조 공정 기술 근황을 자세히는 모르지만, 삼성전자는 이 문제를 3차원 구조로 해결할 생각이다. 일례로 삼성전자는 NAND 플래시 메모리를 128단으로 수직 적층해 회로 선폭 미세화의 한계를 극복하고 있다. 메모리 셀의 크기를 더는 줄이기 어려우니 빌딩 짓듯 수직으로 쌓는 것이다. 물론 이 빌딩을 1024층이나 4086층 정도까지 높이 쌓기는 어렵겠지만, 하여간 2차원 미세화가 어려움에 봉착하자 3차원으로 눈을 돌리게 된 것이다. 실리콘 칩 적층은 이미 시작돼 점차 그 층수가 늘고 있으며, 실리콘 관통 전극(TSV) 기술을 활용해 여러 개의 실리콘 다이를 수직으로 적층하고 실리콘을 관통하는 터널을 뚫은 뒤 전도층을 형성해 신호 처리 과제를 해결한다.
그런데 AI 반도체에서는 더 복잡한 문제가 발생한다. 행렬 연산에 대한 수요가 늘면서, CPU의 처리 방식만으로는 고급 AI 연산 수행이 어렵다는 게 그것이다.
과거 80386 CPU는 곱셈은 덧셈을 여러 차례 수행하고 나눗셈은 뺄셈을 시프트 해 처리했다. 이후 나온 80486 CPU는 32bit 코프로세서 1개를 내장해 가감승제를 한 클록에 수행했다. 반면 GPU의 경우 곱셈과 덧셈 연산에 더 적합하다. 그래픽은 2차원과 3차원 변환을 위해 2×2 혹은 3×3 행렬 연산을 처리해야 하기 때문이다.
GPU는 점점 고성능화되고 있다. 컴퓨터 화면 해상도가 640×480, 800×600, 1024×768, 1280×1024, 1600×1200, 1920×1080, 3960×2048로 늘어 왔고, 최근 8K 모니터가 출시되는 등 화면 픽셀은 2제곱 단위로 점점 증가하는 추세이며, 이제 사람들은 4~8K 모니터를 넘어 16K 모니터의 등장을 기다린다. 여기에 과거 초당 16장 정도의 필름 전환에 그치던 디스플레이 주사율이 어느덧 180㎐에 이르렀다. 스마트폰에서도 120㎐ 주사율을 지원하면서, 일상에서도 고해상도 고주사율 디스플레이를 지원하는 높은 행렬 연산 성능 갖춘 GPU의 역할이 중요해졌다.

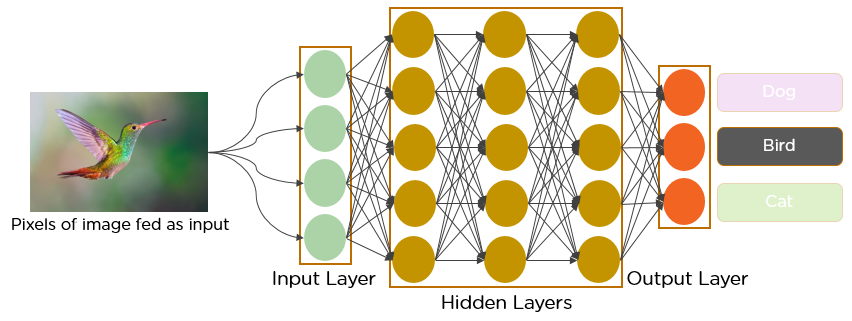
AI 반도체를 언급하기에 앞서 CPU와 GPU에 대해 언급한 이유는, AI 처리도 행렬 연산과 같기 때문이다. 인간의 뇌에서 일어나는 신경세포 사이의 신호 전달을 모방해 y=a×x+b 같은 행렬 구조로 단순화하고, 이를 컨볼루션 연산하거나 딥러닝을 사용해 학습한 것이 AI 모델이 된 것이다.
인간의 두뇌에 존재하는 신경세포와 교세포 수백 수천억 개 만큼의 트랜지스터·회로가 AI 반도체 칩에 집적되는 날이 올까? 반도체 공정이 1㎚급 미세화와 3D 수직 적층을 시도하고, 이렇게 제조된 반도체를 고속 병렬 처리하면 인간과 유사한 사고력을 발휘할 수 있을까? 최근 CPU의 동작 속도는 10㎓까지 올라가고 있고, SRAM(내부)과 DRAM(외부)을 같이 사용하면서 DRAM에 AI 연산 기능을 탑재한 PIM(Processing in memory)도 등장했다. 그러나 최대 10㎓에 이르는 고성능 CPU로도 아직 인간의 두뇌를 따라가기는 벅차 보인다. 인간 뇌파가 내는 주파수는 고성능 CPU의 10억 배 낮은 10㎐ 정도인데도 말이다.
필자는 향후 10년간 반도체 미세화가 계속 진행돼 회로 선폭이 1㎚에 도달할 것이라고 본다. SRAM은 용량이 1GB 정도까지 늘고, NAND 플래시 메모리처럼 3차원 적층 구조로 제작되며, 그것도 모자라 웨어퍼 다이를 적층하는 구조가 나올 것이다. 반도체는 계속 집적되고, 미래에는 누구나 소유하는 휴대기기에 탑재된 반도체 칩의 성능이 현재의 페타플롭스(PetaFlops, 초당 1000조 번 연산)급 슈퍼컴퓨터 수준에 이를 것이다.
AI는 인간이 말하는 것, 생각하는 것, 행동하는 것을 스스로 배울 것이고, 인간의 단순 노동은 사라질지도 모른다. 반도체 개발 역사에 맞춰 무제한의 리소스를 사용하는 소프트웨어를 어떻게 개발할 것인가가 심각한 이슈가 될 것이다. 금세기 안에는 사람과 감정을 교감하는 AI까지 등장할지도 모를 일이다.
에디슨의 백열전구 발명으로부터 130년이 흘렀다. 50여 년 만에 반도체 집적도는 수백만 배 올랐고, 2100년에는 지금보다 수백만 배 높은 고집적 반도체가 생산될 것이다.

모 연구자료에 따르면, 사람의 뇌 구조는 우주와 비슷하다고 한다. AI 반도체를 개발하는 필자는 AI 기술이 태양계를 벗어난 타 은하계까지의 여행을 가능하게 만들지도 모를 미래를 상상해 본다.
그래도 삭제하시겠습니까?