


이번 글에서는 효율적인 코드 생성에 대해 살펴보도록 하겠습니다. 이에 앞서 컴파일러 시스템의 구조와 동작에 대해 간락히 알아보아 보고 코드 작성 시 고려해야 할 사항에 대해 살펴보겠습니다.
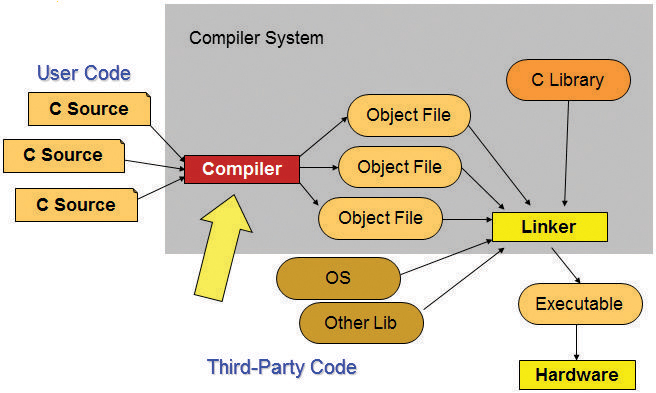
다음의 <그림 1>과 같이 컴파일러 시스템은 C 소스 코드를 오브젝트 코드로 변환하는 컴파일러(Compiler)와 오브젝트 코드를 라이브러리등과 함께 합하여 실행 코드를 생성하는 링커(Linker)로 구성되어 있습니다. 링커과정을 통해서 물리적 어드레스를 할당 받게 됩니다.

<그림2>에서 보이듯 C 소스 코드는 파서를 통해 중간 코드로 변환됩니다. 이 중간 코드 생성 과정에서 높은 수준(High Level)의 최적화 작업이 진행됩니다. 다음은 코드 생성기를 통해 타겟 코드가 생성됩니다.
이때 낮은 수준(Low Level)의 최적화기가 동작하게 됩니다. 이렇듯 생성된 어셈블리 언어를 어셈블러를 통해 기계어로 번역되어 오브젝트 코드가 만들어 집니다. 생성된 오브젝트 코드는 메모리에 대한 절대 어드레스의 할당을 받지 못한 상태입니다.

프로그램의 구조를 보면 디바이스에 독립적인 코드는 별도로 분리하여 작성하는 것이 좋습니다. 그래야 코드의 재사용 및 관리가 용이해 집니다. 그리고 일반 프로그램 파일과 조정된 프로그램 파일로 분리되는데 일반적으로 일반 프로그램 코드는 크기에 대한 최적화를, 조정된 코드는 속도 최적화를 하게 됩니다.
컴파일러가 소스 코드를 분석한다는 의미는 코드의 로직(logic)을 이해한 다는 말과도 같습니다. 제어 흐름에 대한 분석과 데이터 흐름에 대한 분석을 합니다. 실행되지 않는 코드의 위치나 조건식이 항시 거짓으로 판명되는 잘못된 논리인 경우 참에 대한 코드는 dead code가 됩니다. 이러한 내용들을 인지하여 보다 효율적인 코드를 생성하게 됩니다.

앞에서의 코드 최적화를 위해서는 작성한 로직을 정확하게 파악하여 다른 방식으로 구현해야 합니다. 그래야 적은 크기의 코드를 생성하거나 보다 빠른 처리의 코드를 생성할 수 있습니다.
다음은 기본적인 변형 방법에 대한 예제입니다.

실행되지 않을 코드는 삭제되거나 루프 안에서 매개변수와 상관없이 동작되는 코드는 루프 밖으로 이동하여 처리 속도를 높일 수 있습니다.

함수를 호출하기 위해서는 스택에 복귀하여 실행해야할 어드레스를 저장하고 해당 함수로 점프하게 됩니다. 함수에서 처리가 끝나면 스택에 저장되었던 어드레스를 가지고 복귀하게 됩니다.

이렇듯 함수를 호출하기 위한 추가 작업이 필요하게 되는데, 이는 코드의 크기 및 실행 속도를 떨어 지게 만듭니다. 그래서 작은 코드의 함수인 경우는 함수의 코드를 호출하지 않고 직접 코드를 삽입하는 방식으로 사용하는데 이를 인라인 함수라고 합니다.

그리고 정적 클러스터링(Static Clustering)은 코드에서 데이터를 빠르고 쉽게 액세스 할 수 있도록 위치를 조정하는 최적화 방법입니다. 예를 들어 정수 변수 a, b, c가 있다고 가정하면 다음의 실행 코드 중 <그림 8>의 왼편 코드처럼 각 변수의 값을 레지스터로 가져오기 위해 어드레스 정보를 가져오고 나서 해당 번지가 가르키는 값을 가져오는 방식으로 구현하게 됩니다.
그러나 오른편의 코드를 보면 기준 어드레스를 가져온 후 오프셋(offset)으로 변수를 엑세스하므로 적고 빠른 코드를 생성할 수 있습니다.

앞에서 최적화를 위한 변형 방식에 대해 살펴보았습니다. 최적화(optimization)에 대한 설정은 프로젝트 전체 또는 소스 파일 단위로 가능하며 개개의 함수에서 #pragma optimize 명령어를 이용하여 지정할 수 있습니다.
변수 설저에 대한 내용으로 데이터 크기에 대해서는 정확한 크기를 명시하는 것이 좋습니다. 다음의 <그림 10>의 예처럼 8비트 머신과 32비트 머신의 경우 같은 int 형으로 변수를 선언더라도 서로 다른 변수 크기를 갖게 됩니다.
8비트 머신에서는 int형이 16비트의 데이터 크기를 갖지만, 32비트인 경우는 32비트를 차지하게 됩니다. 이러한 데이터 크기의 차이는 표현 할 수 있는 값의 범위가 달라지므로 다른 머신에서 코드를 사용하는 경우 오류를 발생할 수 있어 크기를 명시하여 사용하는 것이 오류를 방지할 수 있습니다.

다음으로는 구조체에서 패딩 바이트(padding byte)에 대해 말씀드리겠습니다. 구조체 foo는 총 5바이트를 사용하고 있지만, 실제로 메모리에 할당되는 메모리의 양은 8바이트가 됩니다.

Byte 구조체 멤버는 1바이트를 사용하지만 얼라인먼트를 맞추기 위해 3바이트의 패딩 바이트가 추가 됩니다. 그래서 실제로 사용되는 메모리는 8바이트를 사용하게 됩니다.
앞에서 정적 클러스터링에 대해 살펴 보았 듯이 전역변수를 사용하는 경우 변수의 주소를 가져오고 그 주소가 가지고 있는 값을 가져오고, 처리된 값을 보관하기 위해서는 같은 동작을 반복해야 합니다.

즉, 주소를 가져오고 그 주소가 가지고 있는 값을 읽어 오거나 그 주소에 값을 저장합니다. <그림 12>는 전역 변수를 효율적으로 사용하기 위한 하나의 예를 보여 주고 있습니다. Auto 변수를 레지스터로 할당하게 설정하고, 전역 변수를 레지스터에 할당된 변수로 복사하여 사용하면 보다 빠른 처리를 할 수있습니다. 그리고 최후 결과를 다시 전역 변수에 넣는 방식입니다.

다음의 <그림 13>에서는 매개변수 및 지역변수의 사용될 수 있는 시기를 표시하고 있습니다. 해당 변수가 사용되는 시점에서만 할당되어 사용 가능합니다. 이 범주를 벗어난 코드 위치에서는 해당 변수를 사용할 수 없습니다.
변수의 어드레스를 가져오기 위해 & 연산자를 사용합니다. 이런 경우는 해당 변수를 레지스터에 할당하여 사용할 수 없습니다. 메모리의 어드레스를 가져야 하기때문입니다.

<그림 14>에서 왼편의 예제 int a 변수는 RAM 메모리 영역에 할당될 것입니다. 그러나 오른쪽의 예제는 temp라는 임시 변수를 이용하여 a 변수를 레지스터로 할당하게 하여 빠른 처리를 할 수있게 합니다.

쉽게 인식할 수 있는 코드가 최적화하기 쉬우며, 유지관리 측면에서도 편리합니다. 그래서 왼편과 같은 Clever 코드는 사용하지말고 이해하기 쉬운 형식으로 코드를 작성해야 합니다.
맺음말
최적화된 코드를 생성하기 위해 컴파일러 시스템의 구현 방식과 효율적인 코드를 작성 하기 위한 팁들을 간략히 살펴 보았습니다. 예시되었던 몇가지의 예로는 부족하지만, 언급되었던 내용들을 고려하여 보다 효율적인 코드를 생성하시길 바랍니다. 감사합니다.
고성용 이사 / IAR 시스템즈
Sung-Yong.Ko@iar.com
그래도 삭제하시겠습니까?