

“저전력, 고성능의 추론·학습 가속용 AI 프로세서 연구 지속할 것”
[테크월드=김경한 기자] 최근 주목받고 있는 AI 알고리즘은 반복되는 대량의 행렬 연산으로 구성된다. 가장 폭넓게 사용되는 GPU는 그 구조상에서 인공지능 알고리즘의 가속에 비효율적이므로, 대량의 행렬 데이터 연산과 전송에 특화된 고속 데이터 전송 구조 설계 아키텍처가 필수적이다.

한편, 플랫폼의 구조적 특성 차이로 성능 최적화 방법이 달라진다. 서버 환경에서는 고성능 요구를 최우선으로 만족해야 하고, 전력이나 폼팩터(form factor)의 제약이 크지 않아 HBM(High Bandwidth Memory) 등 고속데이터 전송 메모리를 도입할 수 있다. 모바일 환경에서는 저전력 요구를 만족해야 하고, 폼팩터의 제약이 크므로 HBM 등을 사용하기 어렵다. AI 알고리즘 자체를 압축하는 방식 등을 통해 메모리 대역폭 요구량 자체를 줄이는 기술, 연산량을 줄이기 위해 희소성(sparsity)을 활용하는 연산기 기술, 연산기 비트수를 줄이기 위한 낮은 비트 정밀도(bit precision) 변환 기술 등이 연구되고 있다.
본 논문은 AI 알고리즘 중 추론(inference) 가속용 인공지능 프로세서의 기술 동향을 소개하고, 국내 인공지능 반도체 대표 성과인 한국전자통신연구원(ETRI)의 VIC(저전력)/AB9(고성능) 칩의 구조를 설명한다.
Ⅰ. 인공지능프로세서 기술 현황
1. 모바일 인공지능프로세서
최근까지 발표된 모바일 AP는 CPU 코어와 GPU 이외에 인공지능 전용 프로세서인 NPU(Neural Processing Unit)를 대부분 포함하고 있다.
화웨이 기린(Kirin) 칩은 다빈치(DaVinci) 아키텍처를 기반으로 3D 텐서 계산 방식에 맞게 구조화된 16ⅹ16ⅹ16 MAC(Multiply-and-Accumulate) 연산기 큐브(cube), 스칼라 ALU, 벡터 ALU, load/store 유닛 등을 포함한다. 각 MAC 연산기는 사이클당 1개의 부동소수점 16-비트 연산이나 2개의 고정소수점 8-비트 연산을 수행한다[1].

삼성 엑시노스(Exynos) 990의 NPU는 NPU 제어기와 2개의 NPU 코어로 구성되며, NPU 제어기는 CPU, DMA, SRAM, 네트워크 제어기를 포함한다. NPU 코어는 1024개 MAC 연산기로 구성되며, 가중치(weight)의 희소성(sparsity)을 활용해 필요한 연산만을 수행할 수 있는 NPU 구조를 제안했다. Inception-v3 신경망으로 3.4 TOPS/W 결과를 보였다[2].

이외에도 ARM은 다양한 AI 응용에 적용할 수 있도록 3가지 사양의 Ethos-N NPU를, CEVA는 DSP를 주력으로 한 AI 엔진인 NeuPro-S를, Gyrfalcon은 PIM(Processing In Memory) 구조 기반의 매트릭스 연산 전용 엔진인 Lightspeeur 2801·2803을, 헤일로(Hailo)는 자체개발 코어 8개로 구성된 헤일로-8을 개발했다. 이처럼 각 회사는 목표로 하는 동작 환경에 최적화된 인공지능 반도체를 속속 발표하고 있다.
2. 서버용 인공지능프로세서
가. 엔비디아(NVIDIA) GPU
엔비디아의 GPU는 SIMT(Single Instruction Multiple Thread) 구조의 SP(Streaming Processor)로 구성된 SM을 n개씩 묶어 연산 단위인 TPC(Texture/Processor Cluster)로 구성한다[3][4]. TPC, SM의 구성 방식에 따라 GPU 모델과 사용 목적이 결정된다. 각각의 SP는 다양한 정밀도를 가지는 부동/고정소수점 연산을 지원하며, 분기 예측기, 계층적인 캐시(Cache) 구조와 일관성 프로토콜(Coherence Protocol)을 가진다. 하지만 CNN, MLP 등의 AI 알고리즘은 일정한 데이터 흐름을 가지고 있어 분기 예측기나 캐시의 효용성이 미약하며, 추론을 위한 연산자들은 단일 데이터 타입이 사용되므로 AI 알고리즘 가속에 있어 GPU는 성능과 전력 소모 측면에서 비효율적이다.
나. 구글 TPU

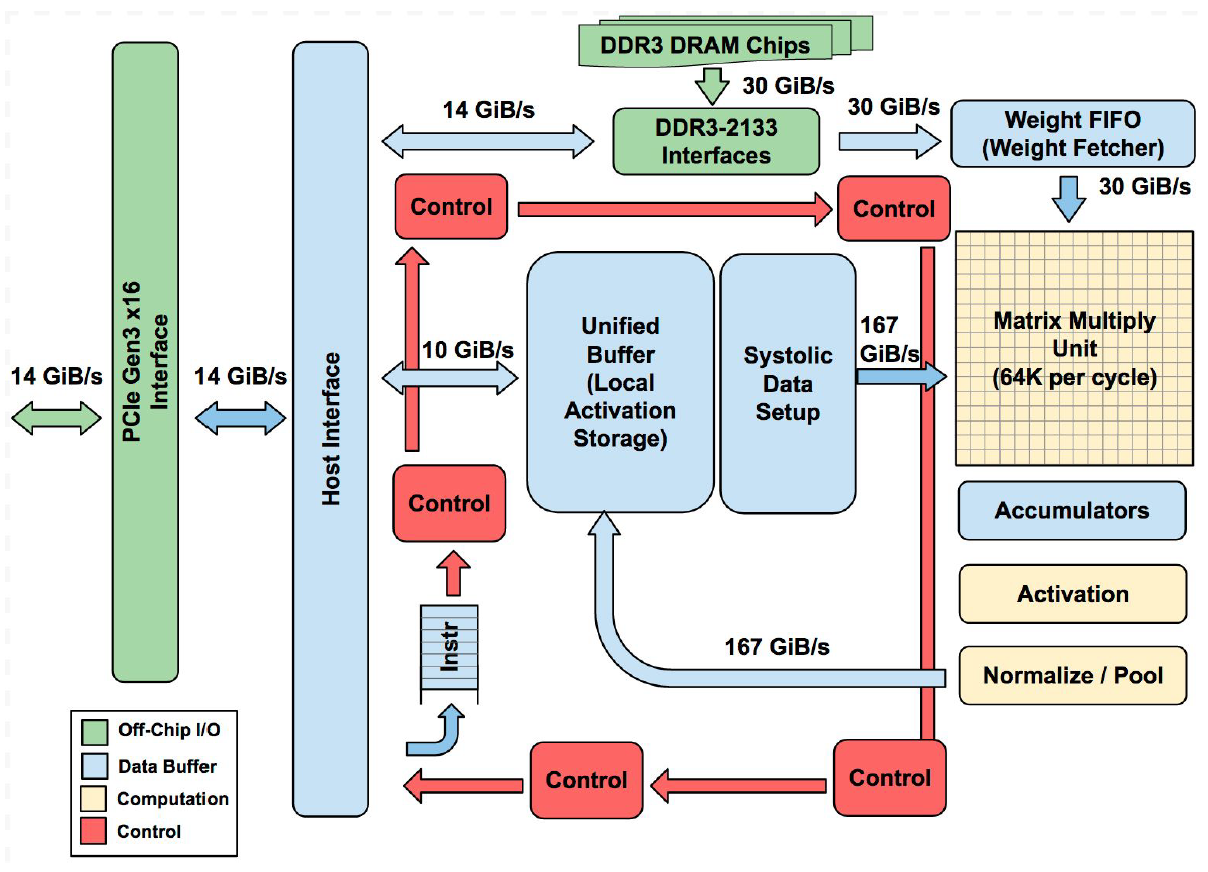
2017년부터 Google은 TPU v1(추론용), v2, v3(학습용)를 발표했으며, TPU v1은 AI 알고리즘 전용 가속 아키텍처로 GPU 대비 30배 이상의 TOPS/W를 달성했다. TPU v1의 연산기 MMU(Matrix Multiply Unit)는 700MHz의 주파수로 8-비트 행렬 MAC 연산을 수행할 수 있는 256ⅹ256개의 PE(Processing Element)가 시스톨릭 배열(Systolic Array) 형태로 배치돼 있다. MMU에 인접한 내부 메모리는 매 사이클 피쳐맵(Feature Map)과 가중치 데이터를 PE로 공급해 그 연산 결과물은 TPU의 어큐뮬레이터(Accumulator)에서 순차적으로 더해진다. 이후 AI 알고리즘에 따라 ReLU, Max Pooling 등의 함수 연산이 수행된 후, 최종 결과물이 Unified Buffer에 저장된다.
MMU 구조상 불필요한 데이터 복사가 최소화돼 Operational Intensity를 높이는 동시에 오직 고정소수점 연산만을 지원하기 때문에, 부동소수점 연산기로만 구성된 아키텍처에 비해 상대적으로 낮은 전력과 면적으로 높은 성능을 얻을 수 있다. 하지만 대부분의 AI 알고리즘은 부동소수점으로 학습(training)되므로 추론 연산 시 고정/부동소수점 간의 형 변환이 필요하다. 이 과정에서 정확도 손실(Accuracy loss)이 발생한다. 이는 자율주행 등 신뢰도가 중요시되는 영역에서 치명적인 약점이 될 수 있다.
Ⅱ. ETRI 저전력 인공지능프로세서
ETRI의 인공지능프로세서연구실에서는 저전력 시각지능 기반 고속 추론을 위한 전용 칩 개발 과제를 수행해 2019년 12월 VIC(Visual Intelligence Chip)을 발표했다. TSMC 40nm LP 공정에서 칩 면적이 5ⅹ5mm로 제작된 VIC은 센서나 경량단말에서 사람 수준의 시각지능 추론 기능 담당을 목표로 개발된 칩이다. 이 칩은 400MHz 동작 속도로 범용 객체 인지(Recognition)와 위치추출(localization)을 실행할 수 있다.
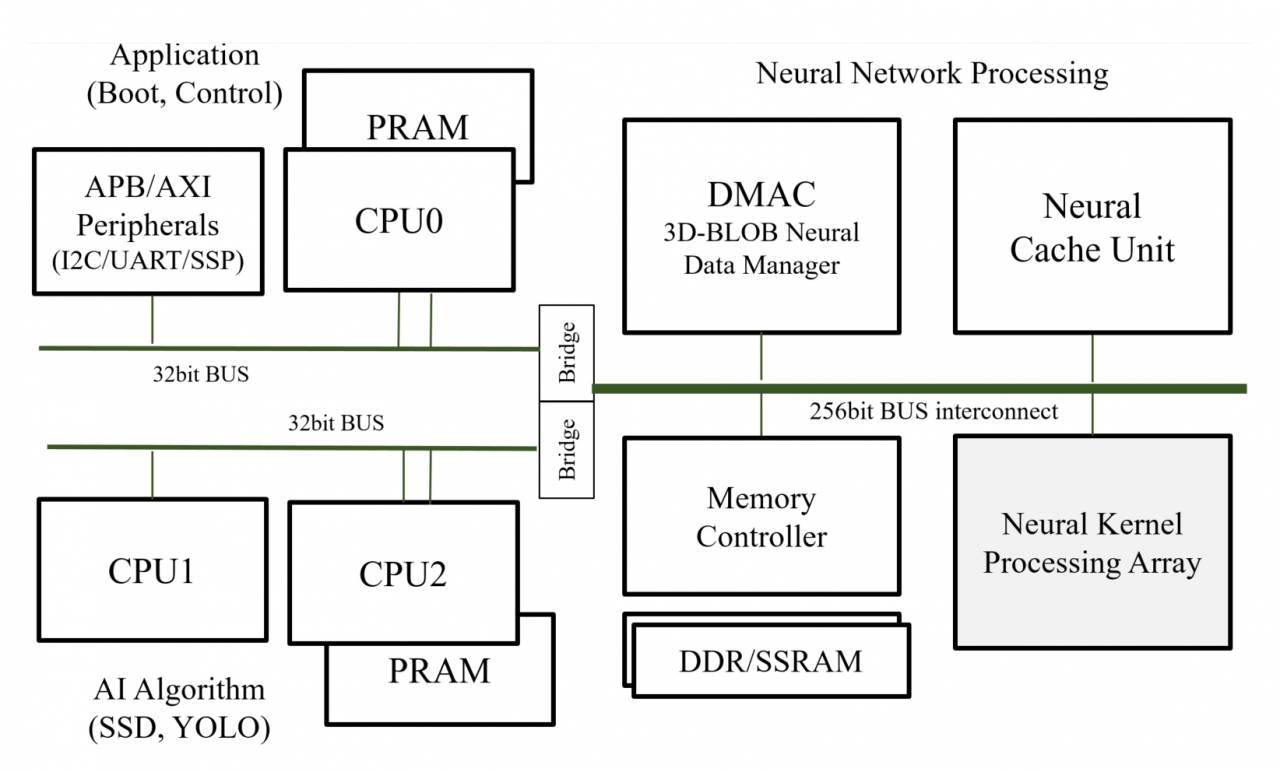
VIC의 내부 아키텍처 구조는 크게 뉴럴 네트워크 프로세싱(Neural Network Processing) 모듈, AI 알고리즘 처리 모듈, 외부장치 연결제어 및 부트(Boot) 제어를 담당하는 애플리케이션 모듈로 구별된다. 세부 모듈은 RISC-V 기반의 CPU 서브 시스템, 고속 데이터 전송을 위해 256/32-비트 계층 버스, 신경망의 연산을 담당하는 커널 PA(Neural Kernel Processing Array), 메모리와 컨트롤러, 고속데이터전송을 위한 DMAC(Direct Memory Access Controller)와 신경망 연산기 전용 캐시 NCU(Neural Cache Unit)로 구성된다. 커널 PA는 대량 병렬 커널 유닛들로 이뤄져 있다. 로컬 메모리인 틸링 캐시 메모리(Tiling Cache Memory)와 ABLAC을 포함하는 아날로그/디지털 혼종 MAC 연산기로 구성돼 있다. ABLAC(Analog Basic Linear Algebra Circuit)는 신경망 연산의 핵심인 MAC 연산기를 저전력으로 설계하기 위한 아날로그 연산기로 2.36pJ(1.21mW, 512 MSOP/s)의 저전력 동작 성능을 보인다.

VIC 동작을 위한 시냅스 컴파일러는 저전력 고속 동작을 위해 신경망의 가중치 데이터 중 제로(zero) 값을 연산에서 제외하는 기능을 수행하며, 신경망을 프루닝(pruning)하고 재학습하는 과정에서 희소성을 도출한다. 신경망 압축 효율을 올리기 위해, 양자화, 가중치 데이터 그룹화, 계층 퓨징(layer Fusing) 기능 등을 포함하며 확장성을 고려하여 공개 소스 딥러닝 프레임워크인 카페(Caffe)를 기반으로 개발됐다. 이를 바탕으로 VIC 칩은 SSD, ResNet, MobileNet, Inception, GoogLeNet 등 다양한 신경망으로 검증됐으며, 신경망을 구성하는 다양한 계층과 연산 커널 구조를 모두 지원한다.

Ⅲ. ETRI 고성능 인공지능프로세서
AB9은 AI 알고리즘을 가속하기 위한 고성능 인공지능 플랫폼으로, 정규 알고리즘 처리용 프로세서인 STC와 범용성 확보를 위한 SPARC ISA 기반 알데바란 CPU 쿼드코어로 구성된다[6]. 메모리 대역폭 확보를 위해 170Gbps의 LPDDR4 채널 2개가 사용된다. 더불어 호스트 시스템과의 통신을 위한 PCIe x16 Gen3 인터페이스, CNN 기반 AI 알고리즘을 위한 HDMI 비디오 입출력, 데이터 저장을 위한 저장장치·제어기, 자율주행용 CAN 인터페이스 등의 주변 장치들로 구성된다. TSMC 28nm 공정에서 패키지 면적 33ⅹ33mm(Die 면적은 19ⅹ26mm)로 제작된 AB9는 총 2.85억 Gate Count, Power/Ground를 포함 Primary IO pin 총 1599개, 1V의 동작 전압, 섭씨 -40~125도의 동작 온도 등의 스펙을 지닌다. STC는 크게 내부 제어를 위한 FC(Flow Control), 연산 유닛인 SA(Systolic Array), 데이터 저장을 위한 DC(Data Control), DMA를 위한 MM(Memory Mover)으로 구성된다.

FC는 외부로부터 전달받은 NC 명령어를 저장하기 위한 NCSEQTBL과 DC 읽기/쓰기를 위한 주소를 생성해주는 AG로 구성된다. NCSEQTBL은 32-비트의 NC 명령어를 1024개까지 저장할 수 있는 FIFO 구조이며, NC 명령어를 통해 각 NC의 내부 데이터 흐름(data flow)을 재구성할 수 있어 다양한 종류의 AI 알고리즘(convolution, fully-connected, LSTM 등)에 대응할 수 있다. 합성곱 연산에 필요한 DC 주소는 입출력 피쳐맵, 가중치 각각의 폭(width), 높이(height), 깊이(depth) 등 총 7가지이며, 7차원의 중첩 반복 루프(nested loop)로 구성된 AG를 통해 매 사이클마다 생성된다. 각 차원에서는 3가지 변수(시작 주소, 오프셋, 루프 수행 횟수)에 의해 주소 생성 패턴이 결정되는데, 각 변수는 모두 프로그램 가능하므로 현존하는 CNN 기반 AI 알고리즘 대부분을 지원할 수 있다.
SA는 1.2GHz로 동작하는 16-비트 부동소수점 MAC 연산용 NC(Nano-Core)들이 128ⅹ128의 시스톨릭 배열 구조로 배치돼, MAC을 2개의 오퍼레이션으로 계산해 총 40 TeraFLOPS(Floating-point Operations per second)의 성능을 가진다. 각 NC는 16-비트 부동소수점 곱셈(multiply), 덧셈(add), 비교(compare), 최댓값(max) 연산을 지원한다. 또한, 누설전력 차단을 위해 파워 게이팅(Power Gating) 기능을 지원, SA의 파워 도메인(Power Domain)을 16개로 나눠 병렬적으로 PG 제어할 수 있도록 설계함으로써 전력 공급/차단 시의 지연시간을 최소화한다.

DC는 피쳐맵과 가중치 데이터를 저장하기 위한 32MB 크기의 내부 SRAM과 이의 제어 로직으로 구성돼 있다. SA와 같은 128행으로 구성되며, 각 행은 8개의 병렬적 읽기/쓰기가 가능한 독립적인 256KB SRAM 뱅크(Bank)로 세분된다. FC로부터 피쳐맵과 가중치 데이터 주소가 전달되면, 각 DC는 해당 위치의 데이터를 NC에 공급한다. 피쳐맵과 가중치가 모두 단일 DC에 저장되므로 피쳐맵과 가중치 간 데이터 용량 비율과 무관하게 내부 메모리를 효과적으로 관리할 수 있다.
MM은 256-비트의 읽기/쓰기를 지원하는 DMA(Direct Memory Access) 모듈로써 외부 LPDDR4/PCIe와 DC 사이의 인터페이스를 담당한다. MM0는 외부로부터 읽은 피쳐맵을 DC에 저장하거나, DC에 저장된 출력 데이터를 다시 외부로 전송하며, MM1은 외부로부터 가중치 데이터만을 DC로 이동시킨다.

Ⅳ. 맺음말
AI 알고리즘의 고도화에 따라 거대한 연산의 효율적 처리 기술의 중요도는 나날이 증가하고 있다. 이를 위해 모바일/서버 등 AI 서비스가 적용되는 플랫폼의 특성을 고려한 인공지능프로세서 연구가 활발히 진행되고 있다. 기존의 고전적 아키텍처인 CPU와 GPU만으로는 행렬 연산 처리를 효율적으로 진행할 수 없어, 인공지능 전용 가속 아키텍처인 NPU(Neural Processing Unit)가 개발됐다. 이에 학계와 산업계는 인공지능 응용 분야에 따라 NPU의 기능을 강화한 독자적 상품을 내놓고 있다.
ETRI에서는 독자적 프로세서 설계 기술을 바탕으로, 2.4pJ/SOP의 저전력 동작 성능을 가지는 VIC과 최대 2.7TFLOPS/W의 전력 효율을 가지는 고성능 AB9 등의 인공지능 반도체를 개발했다. AI 알고리즘의 학습을 가속할 수 있는 고성능 인공지능프로세서와 On-chip 학습을 위한 저전력 인공지능프로세서에 대한 요구가 증대됨에 따라, 향후 ETRI에서는 다양한 사용 환경에 적합한 저전력-고성능의 추론-학습 가속용 인공지능 프로세서에 관한 연구를 지속할 예정이다.

글: 이미영 인공지능프로세서연구실 책임연구원 sharav@etri.re.kr
정재훈 인공지능프로세서연구실 연구원 jchung@etri.re.kr
이주현 인공지능프로세서연구실 책임연구원 juehyun@etri.re.kr
양정민 인공지능프로세서연구실 선임연구원 jmyang38@etri.re.kr
한진호 인공지능프로세서연구실 실장 soc@etri.re.kr
권영수 지능형반도체연구본부 본부장 yskwon@etri.re.kr
자료제공: 한국전자통신연구원(www.etri.re.kr)
- 이 글은 테크월드가 발행하는 월간 EPNC 2020년 6월호에 게재된 기사입니다.
그래도 삭제하시겠습니까?