

자일링스
프로세서 성능을 가속시키기 위해 원래의 하드웨어를 변화시킬 수 있는 수많은 알고리즘이 존재한다. 주어진 시간 범위 내에서 최소 혹은 최대한의 가치를 만들어 내는 일반적인 표준 편차 알고리즘의 전형인 필터와 FFT 알고리즘은 특별한 노력을 기울이지 않고도 하드웨어로 이식이 가능하다. 하지만 비트 반전(Bit Reversing)과 같이 그리 일반화되어 있지 않은 알고리즘도 적합한 하드웨어 가속기로 이행시킬 수 있다.
글: 카스텐 트로트(Karsten Trott)
자일링스 FAE(Field Application Engineer)
www.xilinx.com

자일링스의 유연한 임베디드 시스템은 FPGA 기반 솔루션에 쉽게 하드웨어 가속기를 구현할 수 있다. FPGA가 가지고 있는 높은 연산 성능으로 어떠한 표준 프로세서나 컨트롤러, DSP를 능가하는 시스템을 만들 수 있다.
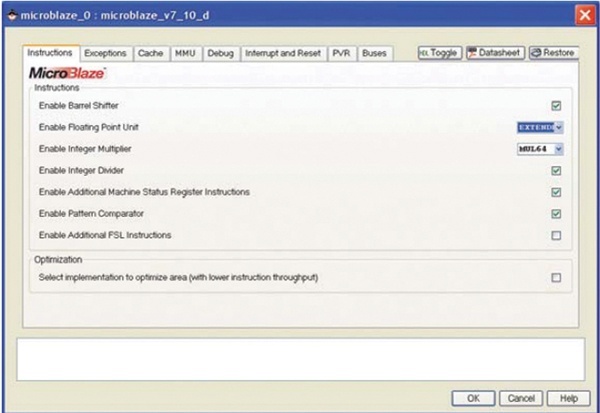
MicroBlaze™ 프로세서는 자일링스가 EDK(Embedded Development Kit)에서 제공하는 2개의 32bit 코어 중 하나로 하드웨어 가속기를 구현하는데 매우 적절한 매개체이다. 일반적인 MicroBlaze 디자인은 코어 자체에 32bit 멀티플라이어가 포함되어 있는 그림 1에 나타낸 것과 비슷하지만, FPU(Floating-Point Unit)나 배럴 쉬프터(Barrel Shifter), 특별한 하드웨어 가속기는 아니다. 스파르탄(Spartan짋) FPGA 디바이스용 디폴트 시스템은 공간에 최적화된 MicroBlaze 버전(3-스테이지 파이프라인 사용)을 이용해 설계를 시작하지만, 대부분의 고객들은 종종 성능 평가를 수행하기 위해 속도에 최적화된 버전(5-스테이지 파이프라인)으로 작업을 착수하게 된다. 이는 소형인데다 간단하지만 쉽게 확장될 수 있다.
고객들이 프로세서 디자인상에서 요구했던 몇 가지 실제 사례를 통해 하드웨어 가속을 위한 MicroBlaze의 성능을 볼 수 있을 것이다. 우리는 FPGA 솔루션을 표준 컨트롤러 코어와 비교한다 하더라도 가격 대비 높은 성능을 구현할 수 있는 스파르탄 디바이스의 시연에 중심을 두고자 한다. 하지만 이러한 기법을 버텍스(Virtex짋) FPGA에도 동일하게 적용할 수 있다.
비트-반전 알고리즘 구현
unsigned int v=value;
unsigned int r = v;
int s = sizeof(v) * CHAR_BIT - 1;
for (v >>= 1; v; v >>= 1)
{
r <<= 1;
r |= v & 1;
s;
}
r <<= s;
return r;
첫 번째 애플리케이션 사례를 위해 MicroBlaze 프로세서가 단지 50MHz로 동작한다고 가정해 보자. 이는 어떠한 스파르탄-3 혹은 스파르탄-6 디바이스라도 매우 쉽게 구현할 수 있는 것이다. 로컬 메모리 버스(명령어 및 데이터 LMB)와 같은 모든 내부 버스뿐만 아니라 PLB(Processor Local Bus)도 마찬가지로 50MHz로 동작한다. 간단하게 만들기 위해 부가된 외부 DDR 메모리가 없다고 가정하자.
이제 해당 CPU 상에 비트-반전 알고리즘을 구현하고자 하는 고객들을 생각해 보자. MicroBlaze 자체는 이러한 기능을 하드웨어를 통해 직접 제공하지는 않는다. 추가로 비트 반전이 초당 2만 번 수행된다고 가정해 보자.
이러한 문제를 해결하기 위해 대부분의 고객들은 필요한 기능을 구현하기에 가장 편리한 방법인 순수한 소프트웨어적 구현법을 먼저 채택할 것이다. 그리고 만약 성능이 충분하다면, 어떤 것도 바꿀 필요는 없다.
이러한 목적을 가지고, 단순한 소프트웨어 알고리즘으로 구현된 소형의 간단한 솔루션을 가지고 시작해 보자. 이는 작고, 우수하며, 이해하기 쉬운 반면, 상당히 비효율적인 측면이 있다. 이 구현은 상당히 잘 된 것이지만, 속도에 최적화된(5-스테이지 파이프라인 사용) Micro Blaze 상에서 싱글 32bit 워드로 알고리즘을 구동하는데 220 사이클이 소요되었다. 필요한 2만 번의 연산을 수행하기 위해서는 대략 50MHz 상에서 88ms가 소요되었다. 고객은 이제 여전히 순순한 소프트웨어 솔루션으로 구현된 것이지만, 약간 다른 접근법을 이용해 알고리즘을 최적화하고자 할 것이다.
unsigned int v=value;
unsigned int r=0;
if (v & 0x00000001) r |= 0x80000000;
if (v & 0x00000002) r |= 0x40000000;
if (v & 0x00000004) r |= 0x20000000;
if (v & 0x00000008) r |= 0x10000000;
if (v & 0x00000010) r |= 0x08000000;
if (v & 0x00000020) r |= 0x04000000;
if (v & 0x00000040) r |= 0x02000000;
if (v & 0x00000080) r |= 0x01000000;
if (v & 0x00000100) r |= 0x00800000;
if (v & 0x00000200) r |= 0x00400000;
if (v & 0x00000400) r |= 0x00200000;
if (v & 0x00000800) r |= 0x00100000;
if (v & 0x00001000) r |= 0x00080000;
if (v & 0x00002000) r |= 0x00040000;
if (v & 0x00004000) r |= 0x00020000;
if (v & 0x00008000) r |= 0x00010000;
if (v & 0x00010000) r |= 0x00008000;
if (v & 0x00020000) r |= 0x00004000;
if (v & 0x00040000) r |= 0x00002000;
if (v & 0x00080000) r |= 0x00001000;
if (v & 0x00100000) r |= 0x00000800;
if (v & 0x00200000) r |= 0x00000400;
if (v & 0x00400000) r |= 0x00000200;
if (v & 0x00800000) r |= 0x00000100;
if (v & 0x01000000) r |= 0x00000080;
if (v & 0x02000000) r |= 0x00000040;
if (v & 0x04000000) r |= 0x00000020;
if (v & 0x08000000) r |= 0x00000010;
if (v & 0x10000000) r |= 0x00000008;
if (v & 0x20000000) r |= 0x00000004;
if (v & 0x40000000) r |= 0x00000002;
if (v & 0x80000000) r |= 0x00000001;
return r;
이 코드는 상당히 길지만 보다 효율적이다. 표준 MicroBlaze 상에서 코드 실행은 싱글 32bit 워드의 경우 130 사이클이 걸렸다. 이는 상당히 개선된 것이지만, 여전히 너무 길다. 2만 번의 연산을 위한 전체 실행시간은 대략 52ms가 되었다.
다음으로 고객은 보다 향상된 알고리즘을 찾기 위해 인터넷에서 조사를 수행했고, 이를 발견했다:
unsigned x = value;
unsigned r;
x = (((x & 0xaaaaaaaa) >> 1) | ((x
& 0x55555555) << 1));
x = (((x & 0xcccccccc) >> 2) | ((x
& 0x33333333) << 2));
x = (((x & 0xf0f0f0f0) >> 4) | ((x
& 0x0f0f0f0f) << 4));
x = (((x & 0xff00ff00) >> 8) | ((x
& 0x00ff00ff) << 8));
r = ((x >> 16) | (x << 16));
return r;
이 코드는 작지만 꽤 효율적으로 보인다. 그리고 파이프라이닝을 깨뜨릴 수 있는 어떠한 브랜칭도 필요하지 않다. 이는 단지 29 사이클로 코어 시스템에서 동작한다.
하지만 알고리즘은 1, 2, 4, 8, 16bit의 쉬프트 연산을 사용해야 한다. 그림 2에 보여진 것처럼 MicroBlaze의 속성 창에서 배럴 쉬프터를 활성화시켜 보자. 배럴 쉬프터를 이용해 단일 사이클 내에서 쉬프트 연산 길이와는 독립적으로 쉬프트 명령어를 실행시킬 수 있다. 이로써 MicroBlaze 상에서 순수 소프트웨어 알고리즘을 약간 빠르게 구동시키는 것이 가능하다.
MicroBlaze 하드웨어에서 배럴 쉬프터를 활성화함으로써 22까지 알고리즘을 처리하는데 소요되는 사이클 수를 감소시킨다. 이는 최초의 소프트웨어 알고리즘 버전에 비해 상당히 개선된 것이다. 이제 알고리즘은 전체 2만 번을 구동하는데 약 8.8ms 만이 소요되며, 이는 10배 정도 향상된 것이지만, 아직 고객들에게는 충분하지 않다.
이는 순수 소프트웨어 솔루션에서 MicroBlaze 코어의 파라미터를 변경하여 지원한다고 하더라도 더 이상의 개선은 어렵다. 이때, 하드웨어 가속기를 완전히 사용할 수 있도록 만드는 새로운 접근법을 통해 순수 하드웨어 솔루션의 효과가 발휘되어야 하는 것이다.
기본적인 연산을 가속하기 위해서는 매우 간단한 코어만이 MicroBlaze FSL(Fast Simplex Link)에 부가되면 된다. 표준 FSL 구현은 MicroBlaze 코어에서 FSL 하드웨어 가속기 IP(Intellectual Property)까지 데이터를 전송하기 위해 동기식 혹은 비동기식 FIFO를 비롯해 FSL 버스를 사용한다. FIFO를 갖춘 FSL 버스는 두 사이드로부터의 액세스를 디커플링한다.
만약 FIFO를 포함한 FSL 버스를 가진 표준화된 구현이 사용된다면, 일반적인 실행시간은 4개의 사이클이 된다: MicroBlaze에서 FSL 버스까지의 데이터를 FIFO 안에 작성하기 위한 하나의 사이클과, FIFO에서 FSL IP까지 데이터를 전송하는 하나의 사이클, FSL IP에서 FSL 버스 FIFO까지 다시 결과를 전송하는 하나의 사이클, 그리고 FSL 버스에서 MicroBlaze로 결과를 읽어 들이기 위한 하나의 사이클이 있다.
MicroBlaze에서 FSL 버스까지, 그리고 FSL 버스에서 FSL IP까지의 연결은 EDK의 그래픽 뷰 내에서 쉽게 생성된다(그림 3 참조).

하지만 여전히 개선의 여지는 남아 있다. 알고리즘에서 지연시간은 중요하며, 가능한 작아야 한다. 그러나 2개의 FSL 버스를 이용한 이 구현법은 여전히 4개의 클럭 사이클을 필요로 한다. MicroBlaze와 하드웨어 가속기 간의 연결을 직접 링크 방식으로 바꿈으로써 오직 2개의 클럭 사이클 만으로 지연시간을 반으로 줄일 수 있다. 이제 FSL 하드웨어 가속기 IP에 데이터를 작성하기 위한 하나의 사이클과 회송된 결과를 읽기 위한 하나의 사이클 만이 소요된다.
직접 링크를 사용할 때는 몇 가지 유념할 점이 있다. 먼저, 코프로세서 IP는 입력을 저장해야 하며, 등록된 방법으로 결과를 제공해야 한다. 여기에는 이러한 연산을 처리하기 위한 FIFO를 갖춘 FSL 버스가 없다는 점도 유의하자.
또한 MicroBlaze와 FSL IP를 서로 다른 클럭 속도로 구동하는 것은 이 경우에 상당히 힘든 일이다. 충돌을 피하기 위해 디자이너는 동일한 속도로 이 둘을 구동시키는 데에 최선을 다해야 할 것이다.
그렇다면 어떻게 FSL 버스를 사용하지 않고 MicroBlaze와 FSL IP를 직접 연결할 수 있을까?
이는 상당히 쉽다. MicroBlaze의 데이터 라인과 하드웨어 가속기를 연결하기만 하면 된다. 그런 다음 필요한 경우 핸드쉐이킹 신호(Handshaking Signal)를 부여한다.
비트-반전 IP를 이용한 경우에는 오직 신호 작성 만이 필요하며, 이 IP는 항상 MicroBlaze의 어떠한 요구에도 충분히 빠르게 대응할 수 있다.
architecture behavioral of
fsl_bitrev is
data value sent by microblaze:
signal data_value :
std_logic_vector(0 to 31) := (others=>′
0′);
begin
FSL_M_Data <= data_value;
process(FSL_Clk)
begin
if rising_edge(FSL_CLK) then
if (FSL_S_Exists = ′1′) then
create the bitreversed data:
data_value(0) <= FSL_S_Data(31);
data_value(1) <= FSL_S_Data(30);
data_value(2) <= FSL_S_Data(29);
...
data_value(30) <= FSL_S_Data(1);
data_value(31) <= FSL_S_Data(0);
end if;
end if;
end process;
end architecture behavioral;
MicroBlaze와 FSL IP 사이에 어떠한 FSL 버스도 사용하지 않은 IP를 부가하기 위해서는 프로젝트의 MHS 파일을 아래와 같이 변경해야만 한다:
BEGIN microblaze
...
PARAMETER C_FSL_LINKS = 1
...
PORT FSL0_S_EXISTS = net_vcc
PORT FSL0_S_DATA = FSL0_S_DATA
PORT FSL0_M_DATA = FSL0_M_DATA
PORT FSL0_M_WRITE = FSL0_M_EXISTS
PORT FSL0_M_Full = net_gnd
END
BEGIN fsl_bitrev
PARAMETER INSTANCE = fsl_bitrev_0
PARAMETER HW_VER = 1.00.a
PORT FSL_S_DATA = FSL0_M_DATA
PORT FSL_S_EXISTS = FSL0_M_EXISTS
PORT FSL_M_Data = FSL0_S_DATA
PORT FSL_M_Full = net_gnd
PORT FSL_Clk = clk_50_0000MHz
END
이제 게임은 상당히 달라졌다. 하드웨어 코어는 오직 2개의 사이클로 비트-반전 연산을 수행할 것이며, 하나의 사이클은 IP에 데이터를 작성하는 것이고, 하나는 이를 다시 읽는 사이클이다. 이제 2만 번의 모든 비트-반전 연산을 프로세싱하는데 단지 0.8ms 만이 소요된다. 이는 아주 초기의 알고리즘 보다 110배 향상된 것이다. 이를 다른 방법으로 적용하기 위해서는 어떠한 측정에서도 상당히 인상적인 최초의 알고리즘을 이용해 동일한 수에서 애플리케이션을 구동할 수 있도록 5.5GHz에서 동작하는 프로세서가 필요할 것이다.
마지막으로 이 접근법을 가장 효과적인 소프트웨어 알고리즘과 비교하면, 시스템은 여전히 11배 더 뛰어나다. 반면 순수 소프트웨어에서 동일한 알고리즘을 실행하기 위해서는 550MHz에서 동작하는 CPU가 필요할 것이다.
물론 이 경우에는 오직 해당 CPU가 비트-반전 어드레싱을 전혀 제공하지 않을 경우에만 유효하다. 대부분의 DSP는 이러한 기능을 가지고 있지만 사실상 마이크로컨트롤러는 그러하지 못하다. 이러한 기능을 추가할 수 있는 능력을 갖춘다면 이러한 알고리즘의 프로세싱 속도를 획기적으로 향상시킬 수 있다.
변화는 작았지만, 상당히 효과적이었다. 또한 오직 2개의 워드로 코드 사이즈를 줄일 수 있었다. 물론 하드웨어를 위한 약간의 슬라이스를 추가하는 것이 필요했지만, 이러한 트레이드-오프는 솔루션에서 어떠한 표준 마이크로컨트롤러 보다 능가하는 향상된 속도를 제공하는데 있어 가치가 있었다.
빠른 부동 소수점 성능
for (i=0;i<512;i) {
f_sum = farr[i];
f_sum_prod = farr[i] * farr[i];
f_sum_tprod = farr[i] *
farr[i] * farr[i];
f_sqrt =
sqrt(farr[i]);
if (min_f > farr[i]) { min_f =
farr[i]; }
if (max_f < farr[i]) { max_f =
farr[i]; }
}
MicroBlaze의 가속 성능을 보여주는 알고리즘의 또 다른 사례에서, 고객들은 MicroBlaze 시스템 상에서 부동 소수점 프로세싱이 상당히 느리게 동작한다는 점에 불만을 가지고 있었다. 이 알고리즘은 즉시 몇 가지 결과를 생성할 수 있는 간단한 루프를 가지고 있었다.
모든 값은 단정밀(Single-Precision) 부동 소수점의 값이었다. 첫 번째 아이디어는 가장 기본적인 질문에서 시작되었다; 부동 소수점 유닛은 활성 되었는가? 프로젝트 설정을 검토함으로써 우리는 FPU에 여전히 문제가 있다는 것을 발견했다. 이것이 단지 몇 개의 수를 계산하는 데에도 오랜 시간이 걸린 이유였다. FPU의 활성화는 MicroBlaze 고유 설정 내부에서 처리된다(그림 4 참조).
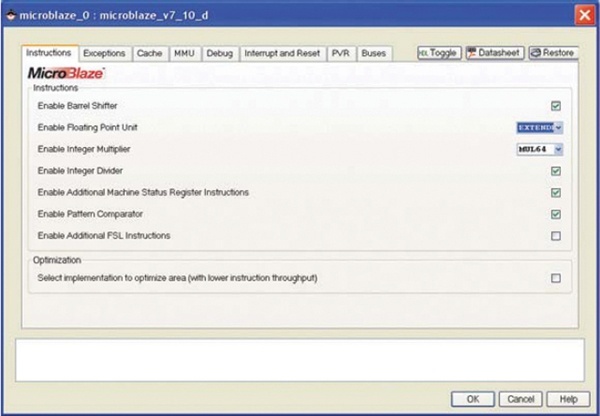
FPU 지원에는 두 가지 버전이 있다. 우리는 sqrt() 연산도 지원하기 위해 확장 FPU(Extended FPU)를 선택했다. 512 값에 대한 전체 루프는 이제 50MHz MicroBlaze 상에서 1,108,685 사이클을 소요했다. 생성된 어셈블러 코드를 간단히 살펴본 결과, math-lib 기능이 여전히 제곱근을 생성하는데 사용되고 있었다. 이는 다음과 같은 연산 기능에서 정의된 것이다.
double sqrt(double);
하지만 고객은 제곱근 기능을 부동 소수점 값을 처리하기 위해서만 사용했다. 따라서 문제를 해결하기 위해 MicroBlaze FPU를 이러한 기능을 처리할 수 있는 새로운 기능으로 정의한 것이다:
float sqrtf(float);
f_sqrt =sqrt(farr[i]);에서 f_sqrt = sqrtf(farr[i]);로 라인을 변경함으로써 FPU 내부의 제곱근 기능을 MicroBlaze 안에서 사용할 수 있게 되었다. 이제 코드는 35,336 사이클로 구동했다. 다시 우리는 사소한 변경을 통해, 특히 FPU를 전혀 사용하지 않았던 최초의 구현방법에 비해 31배 가량 개선할 수 있었다. 동일한 실행시간 안에 이러한 결과를 얻기 위해서는 대략 1.5GHz에서 동작하는 CPU가 필요할 것이다.
하지만 고객은 여전히 만족하지 않았으며, 보다 높은 속도를 필요로 했다. 이 경우에 부동 소수점에서 고정 소수점 연산으로의 알고리즘 변경은 적절한 선택이 아니다. 대신 우리는 프로세싱 루프의 속도를 높일 수 있는 새로운 특별한 하드웨어 가속기(새로운 FSL IP)를 만들었다.
새로운 FSL IP는 4x ADD, 2x MUL, 1x GREATER, 1x LESS, 1x SQRT 연산을 위한 9개의 예를 만들기 위해 CORE Generator™ 모듈 부동 소수점 4.0 버전을 활용한다. 이들 모두 인스턴스화 되며, 동일한 입력 데이터 상에서 완벽하게 병렬로 동작한다(그림 5).

FSL IP 내의 인스턴스는 약간의 내부 지연을 초래하지만, 처리량은 1이다. 이로 인해 가속기 내부의 컨트롤러 하드웨어를 위해 약간의 슬라이스를 추가하는 것이 필요했지만 새로운 모든 데이터 클럭 사이클을 코프로세서로 공급하는 것이 가능하다.
오직 프로세싱 루프의 종단에서만 약간의 추가적인 사이클이 결과를 회수하기 전에 필요하다.
FIFO가 필요 없는 직접 링크를 사용하여 MicroBlaze와 FSL IP를 연결했다. 전송된 모든 데이터 는 IP 내부에서 버퍼링되며, 그 뒤에 즉시 프로세싱 된다.
FSL IP에서 다시 MicroBlaze로의 링크는 FSL 버스를 이용해 생성되었다. 이는 구현하기가 더 쉬웠는데, 몇몇 결과를 다시 보내야 하기 때문에 IP 내에서 처리하는 것이 더 간단하다. CoreGen 모듈의 일부는 실행 시간이 추가되어 약간의 지연시간을 갖는데, 이는 완벽하게 getfsl() 요청으로 커버된다. MicroBlaze는 모든 결과가 FSL 버스 FIFO 안에 저장될 때까지 기다리기만 하면 된다. 하지만 데이터 속도가 1이라면 필요한 처리량을 달성하는데 문제가 없다.
FSL 버스의 추가 지연은 크게 부담은 없다.(오직 몇 사이클에 불과) FSL IP를 이용하기 위한 C 코드는 아래와 같다:
for (i=0;i<512;i) {
putfsl(farr[i],fsl0_id);
}
// get the min,max values:
getfsl(min_f,fsl0_id);
getfsl(max_f,fsl0_id);
// get the sum and products:
getfsl(f_sum,fsl0_id);
getfsl(f_sum_prod,fsl0_id);
getfsl(f_sum_tprod,fsl0_id);
getfsl(f_sqrt,fsl0_id);
이 알고리즘의 최종 구현에서는 약 4,630 사이클 만이 소요되었다. 이는 여전히 완전한 부동 소수점 구현방법이다.
이 하드웨어는 하드웨어 가속기를 구현하기 위해 추가적으로 슬라이스를 사용함으로써 모든 결과를 병렬로 산출해 낸다. 하지만 결국 확장 FPU 구현과 비교해 약 7.6 비율로 향상된 결과를 얻을 수 있다. 반면 50MHz 프로세서를 표준 프로세서로 대체하면 대략 380MHz에서 구동하는 CPU가 필요할 것이다.(하드웨어에서 부동 소수점 sqrt 함수를 가졌다고 가정)
이러한 사례에서 알 수 있듯이, 가끔은 작은 변경으로 알고리즘 프로세싱에서 상당한 효과를 얻을 수 있다. 또한 이를 구현함으로써 고성능 DSP와 경쟁할 수 있는 50MHz MicroBlaze 시스템을 만들 수 있다.
먼저, 실행시간이 너무 길게 소요되는 코어 알고리즘이 무엇인지 확인한 다음, 간단하게 소프트웨어를 변경하던지 혹은 하드웨어를 사용하거나 하드웨어 가속기를 이용해 보다 복잡한 변경을 시도함으로써 속도를 향상시킬 수 있다. 이러한 프로세서 시스템은 항상 모든 표준 컨트롤러의 성능을 능가하게 될 것이다.
>>> 저자소개
자일링스 FAE인 카스텐 트로트(Karsten Trott)는 독일 뮌헨에서 근무하고 있으며, 아날로그 칩 디자인 분야에서 박사학위를 취득했으며, 칩 디자인 및 합성 분야에서 탁월한 경험을 가지고 있다. 연락처는 이메일 Karsten.Trott@xilinx.com이다.
회원가입 후 이용바랍니다.
개의 댓글
댓글 정렬
BEST댓글
BEST 댓글
답글과 추천수를 합산하여 자동으로 노출됩니다.
댓글삭제
삭제한 댓글은 다시 복구할 수 없습니다.
그래도 삭제하시겠습니까?
그래도 삭제하시겠습니까?
댓글수정
댓글 수정은 작성 후 1분내에만 가능합니다.
내 댓글 모음